Glow data infrastructure 的演化
Glow 一向是一个 data driven 做决策的公司,稳定高效的平台是必不可少的支撑, 本文总结几年里公司 data infrastructure 的演进过程.
结合业务特点做技术选型和实现时候的几个原则:
- real time 分析的需求不高,时间 delta 控制在1 小时以内可接受 .
- 支持快速的交互式查询.
- 底层平台尽量选择 AWS 托管服务, 减少维护成本.
- 遇到故障, 数据可以 delay 但不能丢.
- 可回溯历史数据.
- 成本可控.
用到的 AWS 服务:
- 数据存储和查询: S3, Redshift (spectrum), Athena
- ETL: DMS, EMR, Kinesis, Firehose, Lambda
开源软件: td-agent, maxwell
数据来源:
- 线上业务数据库
- 用户活动产生的 metrics log
- 从各种第三方服务 api 拉下来的数据 (email之类)
最早期
刚开始的时候业务单纯,数据量也少, 所有数据都用 MySQL 存储,搭了台 slave, 分析查询都在 slave 上进行.
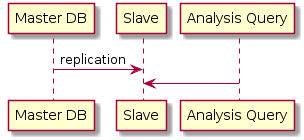
优点是简单, 缺点也很明显:
- 无法支撑大数据量
- MySQL 语法太弱, 不利于分析
- metrics log 和业务数据库不在一起, 无法做 join
- 贵
引入 Redshift
随着业务发展,MySQL 已经放不下 metrics log 了,更换更大的 instance 不划算, 性能也跟不上,算个 retention 要半个小时, 每天的 metrics report 越出越慢.
这个阶段,我们要引入数据仓库, 用了 AWS 的 Redshift.
当时也写过关于 Redshift 使用和优化的文章: redshift as data warehouse
几个考虑:
- columnar storage 减少存储成本, 提高查询效率 (metrics log 设计成了很宽的 flatten table)
- 基于 Postgresql, 有现成的 GUI 客户端和 driver, SQL 语法也比 MySQL 强.
- 和 S3 良好的交互(load/unload data), 方便 ETL.
- 现成的集群支持,可以横向扩容.
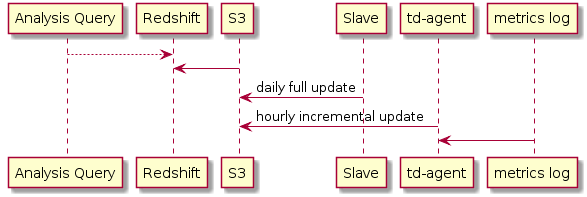
现在,我们可以把线上数据和 metrics log 放在一个 DB 里了,极大简化了分析查询.
metrics log 是 append-only 的数据,不会修改,所以直接用每小时的 cronjob 导进 Redshift, delay 1 小时, 解决了 metrics log 量大的问题.
这一阶段, 线上数据库仍旧不算很大,做所有表的每天全量更新可以接受,数据延迟在1天,实现上是自己写的脚本把数据 dump 到 S3, 再 copy 进 Redshift.
但是每天的 metrics report 中很多指标是需要最新数据的,一天的延迟不能接受, 怎么办? 自己写了个很简单的基于 DAG 的 ETL 管理框架, 在 report 中指定依赖的 table, 跑 report 前会先把依赖的 table 导完保证里面有最新数据,其余没有被依赖的 table 就慢慢导.
当前阶段的问题:
- 业务数据库1天的 delay 对分析可接受,但是 QA 和 developer 有时也会需要这些数据做 debug, 1 天就不够了.
- 业务数据库全量更新, 只是当前阶段可接受, 长远来看不行.
- metrics log 增量很快, 现在是全存 SSD 的 Redshift 集群, 可预见的未来当前架构成本会很高.
减少 metrics log 的存储成本
metrics log 存进 Redshift 之后, 因为能对数据做按行压缩, 存储成本已经比之前 MySQL 低很多了, 我们的压缩比大概在 1:5.
但数据增长实在太快,Redshift 扩容了几次之后, 我们觉得有必要消减成本.
metrics log 是基于时间的数据, 产品分析一般也就需要最近几个月的数据,半年前的数据偶尔会用下, 所以新数据是 hot spot, 老数据就比较冷, 考虑将老数据迁移到便宜的存储方案上去,速度慢点也能接受.
当时的做法, 是另起了一个 HDD 的集群来存储老数据.SSD 集群只保留最近几个月的数据. 算下来存储大概少了30% 的费用,长远看省的更多.
带来的问题:
- 2 个集群,管理成本上升.
- 为了做分析, 线上数据库在两个集群中都复制了一遍, 太冗余.
- HDD 集群迟早也是要扩容的.
减少线上数据库到 Redshift 的 delay
前面说过线上数据库是每天全量更新到 Redshift 的, 随着时间的推移, ETL 运行的时间越来越长, 要想办法做增量更新.
原理很简单,拉 MySQL 的 binlog, 解析后就能增量更新 Redshift 里数据了, 正好 AWS 的 DMS 差不多在这时候支持将数据导入 Redshift 了, 所以就把这块的 ETL 迁移到 DMS 上去.
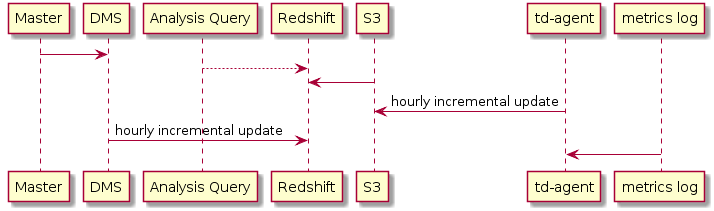
解决了:
- 线上数据 delay 过长
- metrics report 不再需要关心依赖哪些 table
- 简化 ETL
几个注意的地方:
- DMS 默认更新频率大概 1 min 一次, 但我们的 Redshift 里几乎每时每刻都有 分析的 query 在跑,而 Redshift 并发上限比较低(50qps), 实测 DMS 对 Redshift 性能影响很大, 所以我控制了 DMS 的更新频率到 1 小时, 可以调节它的 BatchApplyTimeout 实现.
- Redshift 添加新列只能在表末尾, 而且不能改现有列属性, MySQL 里做 DDL 会导致 DMS task 失败, 可以单独把做 DDL 的表 reload.
- DMS 的配置很复杂,一定要用代码管理起来,不要手工设置, 我用 terraform 来管理 AWS.
淘汰掉 HDD 的 Redshift 集群
HDD 的 Redshift 虽然减少了成本,但带来了管理的复杂, hive 和 postgresql 支持 external table, Redshift 也能用多好?
17 年 4 月的时候, Redshift 发布了 spectrum, 终于支持拿 S3 上数据做 external table 啦.
决定把老的 metrics log 数据搬到 S3 上去, 关于 spectrum 的使用, 和 athena 的关系,以前也写过: 使用 Redshift Spectrum 查询 S3 数据
每月把上个月的 metrics log 导到 S3 上,用 parquet 格式存储(通过EMR 用 spark 转).parquet 是 columnar 的格式, spectrum 是按扫描数据量收钱的, 比较省钱,同时还能大大加快查询速度.

好处:
- 解决了两个集群带来的管理复杂.
- 用 S3 做 data lake,价格进一步降低.
- 新老数据在一个 DB 里, 方便查询和 join.
线上数据的 Audit
对于部分关键业务表(支付相关),我们希望从 DB 层记录下它的所有历史更改, 所以需要记下 binlog, 以前也做过,不过只是单纯得把 binlog 拉下来,存到 S3 上去, 由于存的是裸数据,要看比较麻烦.
希望能直接在 redshift 里查询 MySQL 任意一张表的 binlog.
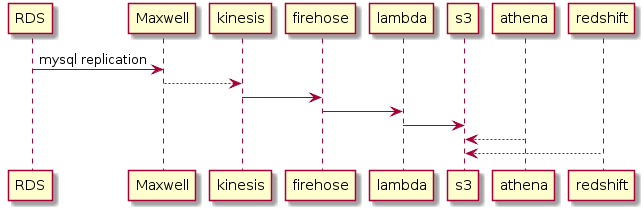
上图看上去流程很长,是因为这是个一天里完成的速成方案, 其实可以优化.
maxwell 是zendesk 开源的一个组件,可以收集 MySQL 的binlog 发送到多种 target (redis/rabbitmq/kiness…)
kinesis 是 AWS 的消息队列服务,firehose 是 AWS 的 ETL 服务, 用来将 data stream 传输到各种存储系统.
firehose 和 S3 之间为什么夹了个 lambda? 这是因为 firehose 比较傻, 它会一次 flush 多条记录到 S3 上,但每条之间没有分隔,直接拼在一起,所以多条 json 记录变到1行去了, athena 和 redshift 都无法识别. 官方建议在数据源头给每条最后加个\n, 但我又改不了 maxwell 的输出格式,只能先拿 lambda 凑合下.
在 athena 和 redshift 里都对 s3 做了 external table, 原因是在当前的数据格式下(每条记录都是嵌套的json) athena 里查询更方便, 因为它是基于 presto 的, 支持嵌套 struct 和 map 结构, 目前 redshift 支持 delimiter 分隔的数据, 实际使用时候需要用一些内置函数提取特定字段, 不是很方便, json 支持在 roadmap 上, 目前还是 athena 更方便.
在 ETL 部分,可以把 firehose 和 lambda 去掉, 自己订阅 kinesis 的数据实现上传 s3.
总结
以上是 Glow 最近几年基于 AWS 构建 data infrastructure 的过程. 实际实施过程中,最麻烦的还是系统迁移时候老数据的 migration, 在刚转换过去的时候难免会碰到一些坑, 积极试错很有必要.