之前用过 datadog 的 tracing 功能, 非常好用, 但是很贵(单台30$), 迁移到 k8s 后, 监控迁移到了 prometheus, 也把 datadog 的 tracing 去掉了.datadog 的 tracing 也是 opentracing 的一种实现, 索性就换上开源实现.
tracing 系统是分布式系统中很好用的 performance tuning 工具, opentracing 只是一个标准,里面定义了 span, scope, tracer 等概念,但不规定 tracing 数据应该怎么 encoding, 怎么存储, 跨进程的 span 数据怎么串起来.
首先要挑选一个开源的 tracer 实现,tracer 用来接受业务系统发出的 encode 过的 span 数据,并存储,提供一个界面供查询. 我选的是 jaeger, go实现的,部署起来比较轻量级, 也是 cncf 的项目, 还有个 jaeger-operator 方便部署.
集成 client 端
业务系统是 python 写的,需要把 tracing 数据发送到 jaeger, 需要两个 lib: opentracing-python, jaeger-client-python. opentracing-python 里面只是写了一些空的接口, span 如何 encode, 如何通过网络传送, 在 jaeger-client-python 里面实现.
jaeger-client-python 里面网络部分是基于 tornado 的 ioloop 实现的, 但业务系统基于 gevent 实现, 这两跑一起总有各种奇奇怪怪的问题, 于是我 fork 了一下, 把网络
部分基于 gevent 重写了一下: monsterxx03/jaeger-client-python, 分支 gevent, 用法不变.
初始化:
from jaeger_client import Config
config = Config(
config={ # usually read from some yaml config
'sampler': {
'type': 'const',
'param': 1,
},
'logging': True,
},
service_name='your-app-name',
validate=True,
)
# 会初始化默认的全局 tracer opentracing.tracer
tracer = config.initialize_tracer()
使用:
import opentracing
# 这里得到的 tracer 就是上面初始化的
tracer = opentracing.global_tracer()
with tracer.start_active_span("test") as scope:
scope.span.set_tag('kind', 'client')
...
当 context manager 结束的时候, span 会被刷入内存里的一个队列, 当队列满了, 或设定的 flush interval 到了就会把内容发送到 jaeger.
跨进程 tracing
假设 service A 通过 http 调用 service B, 如何才能把 A 和 B 串起来呢? opentracing 里通过 inject 和 extract 这两个过程来实现.
inject 时会给 SpanContext 注入 tracer id, 然后得到 encode 过的 kv 形式 tracer id, 在调用 service B 时, 我们只要把这个 kv 对设定在
http header 上就行了.
在 service B 里通过 extract 来从 http header 里根据 tracer id 生成新的 SpanContext, 两个 service 就串起来了.
service A:
with tracer.start_active_span(call) as scope:
scope.span.set_tag(tags.SPAN_KIND, tags.SPAN_KIND_RPC_CLIENT)
scope.span.set_tag('webrpc_client', self.service_name)
carrier = {}
tracer.inject(scope.span.context, opentracing.Format.HTTP_HEADERS, carrier)
# carrier 已经被填充了 tracer id
resp = requests.get(url, headers=carrier)
service B:
span_ctx = tracer.extract(opentracing.Format.HTTP_HEADERS,
request.headers)
scope = tracer.start_active_span(operation_name,
child_of=span_ctx)
自动 patch
因为系统里会用到大量的第三方 client lib: mysql, redis, requests, urllib…不可能全部改一边, 可以通过 monkey_patch 的形式把那些库最后网络发送的部分替换成带 tracing 的实现, 可以看下 opentracing_instrumentation 这个库, 里面提供了对 requests, redis, urllib, psycopg2, mysqldb 等库的 hook.
有些库里面没有, 也可以自己写一个 patch, 比如 elasticsearch 的 python client, 我们只需要替换 elasticsearch.transport.Transport.perform_request 这个函数就行:
import opentracing
from elasticsearch.transport import Transport
tracer = opentracing.global_tracer()
_origin_perform_request = Transport.perform_request
def _perform_request(self, method, url, params=None, body=None):
op_name = url
span = tracer.start_span(op_name)
span.set_tag('component', 'es-py')
span.set_tag('span.kind', 'client')
span.set_tag('es.url', url)
span.set_tag('es.method', method)
if body:
span.set_tag('db.statement', body)
if params:
span.set_tag('elasticsearch.params', params)
try:
rv = _origin_perform_request(self, method, url, params, body)
except Exception as exc:
span.set_tag('error', True)
span.log_kv({
'event': tags.ERROR,
'error.object': exc,
})
span.finish()
raise
span.finish()
return rv
setattr(Transport, 'perform_request', _perform_request)
界面
最后的使用效果如下, 每一长条就是一个 span, 不同颜色的 span 表示在不同的进程中.
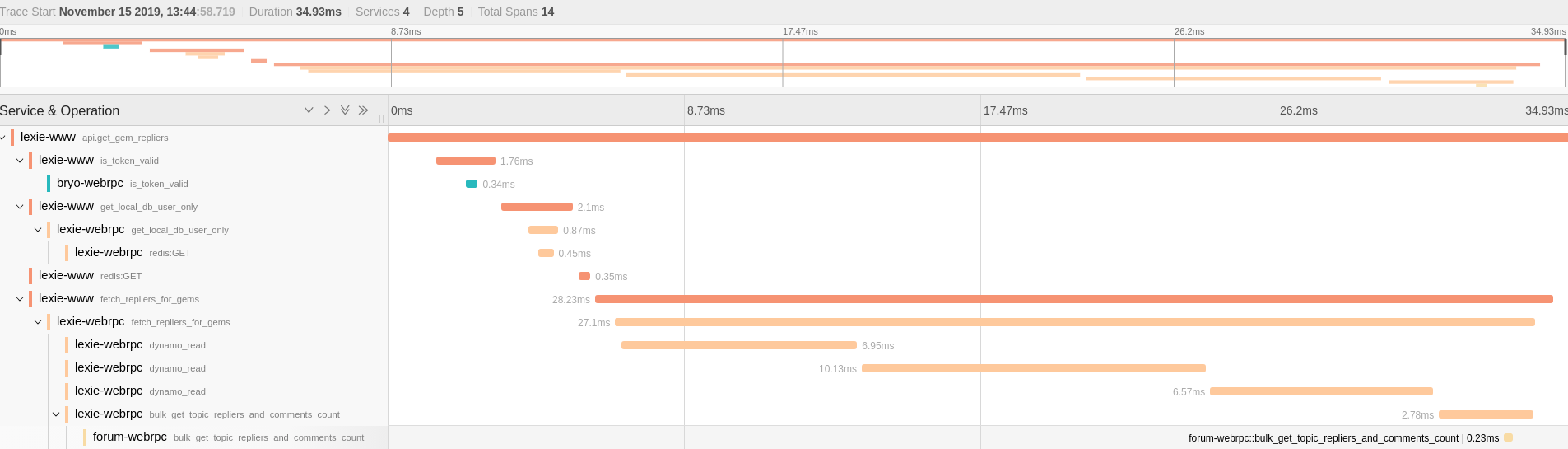
可以很容易的分析在一次 api call 里调用了哪些外部 service, 哪些是瓶颈,是否可以优化. 因为我全部是在发生网络 io 的部分做的 patch, 如果某个 span 的所有子 span 加起来都没有父 span 长, 有空白, 那那段空白就是 cpu heavy 的部分.