最近在把部分用 RDS 的 MySQL 迁移到 aurora 上去, 读了下 aurora 的 paper, 顺便和 RDS 的架构做些对比.
Paper notes
- 存储计算分离
- redo log 下推到存储层
- 副本: 6 副本 3 AZ(2 per az), 失去一个 AZ + 1 additoinal node 不会丢数据(可读不可写). 失去一个 AZ (或任意2 node) 不影响数据写入.
- 10GB 一个 segment, 每个 segment 6 副本一个 PG (protection group), 一 AZ 两副本.
- 在 10Gbps 的网络上, 修复一个 10GB 的segment 需要 10s.
MySQL 一个应用层的写会在底层产生很多额外的写操作,会带来写放大问题:
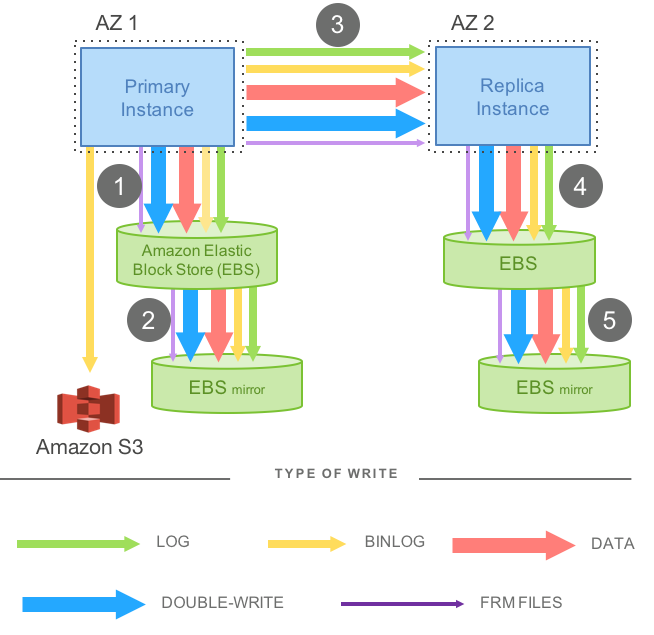
redo log 用来 crash recovery, binlog 会上传 s3 用于 point in time restore.
在 aurora 里,只有 redo log 会通过网络复制到各个 replica, master 会等待 4/6 replicas 完成 redo log 的写入就认为写入成功 (所以失去3副本就无法写入数据了). 其他副本会根据 redo log 重建数据(单独的 redo log applicator 进程).
只同步 redo log 可以大大提高 MySQL 的写能力, 论文中给的数据是,和直接的基于 EBS mirror 的 MySQL 相比, aurora 的TPS 是35 倍, 每个事务产生的 IO 减少了7.7 倍.
每个 redo log 有一个单调递增的 LSN (Log Sequence Number). 一个 PG 里的副本通过 gossip 协议相连, 如果有一个副本缺少部分 redo log, 可以直接从同 PG 内其他副本同步过来.
RDS MySQL
RDS 的 multi AZ 结构
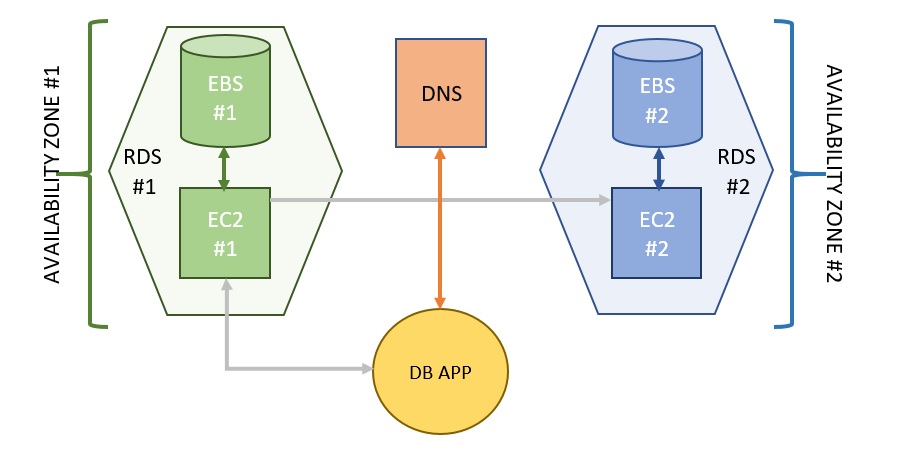
在两个 AZ 里各起一台 EC2 作为 MySQL server, 其中一台为 primary, 通过底层的 EBS 做同步.
应用通过 DNS 域名连接 MySQL, 总是指向当前的 primary, 当发生 failover 时, DNS 自动切换到 standby 的 server, 这个域名的 TTL 很短(5s), 客户端重连后就到了新的 MySQL.
这种结构的问题:
- multi AZ 中的另一台 server 无法作为 read replica, 但要付和 primary server 一样的钱.
- 需要 read replica 的话,要另起一台, 它和 master 之间是通过 binlog replication 同步的, 当 master 在做很耗时的 DDL 操作时, 所有更改都会 pending, 等 master 做完 DDL, read replica 才能开始做 DDL, 然后才继续接受数据.
- EBS 的大小要自己指定, 不够要手工扩容.
- HA 固定在两个 AZ. read replica 最多 5 台
- 单机 size 16TB (EBS 的最大 size).
- standby 的 MySQL 内存中 innodb buffer pool 是空的, 需要时间重建.
Aurora MySQL
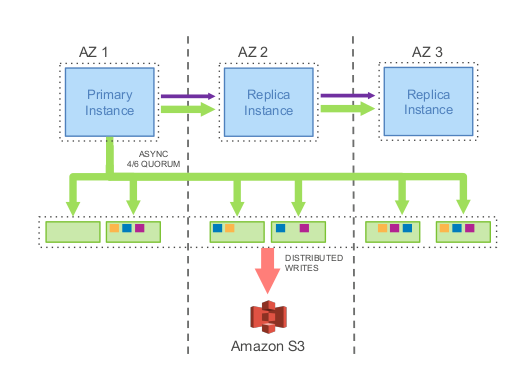
三个 AZ 中 6 副本, 每个 AZ 两副本.
存储计算分离的结构, 集群中 server 的数目不受副本数约束(rds 的 multi az 中就只有 2 副本 2 server, read replica 没法作为 failover 对象). 最多可有 15 个 replicas, 都可作为 failover 对象.
最坏情况可以承受失去一整个 AZ 外加一个额外的副本, 此时整个集群会处于 read only, 但数据不会丢. 失去副本数<3,并且没失去 整个AZ 的情况下, 不会影响读写.
aurora 提供三种访问的 endpoint 域名:
- cluster endpoint: 永远指向当前的 master server, failover 发生时, cluster endpoint 自动刷新.
- reader endpoint: 会自动在 read replicas 之间做 load balancer, 如果只有一台 master, 没 read replicas, reader endpoint 会指向 master, 此时也是可以写入的.
- instance endpoint: 每台 server 单独的 endpoint, 用于访问特定的 server, 但这个就没法做 failover 了.
和 RDS MySQL 比的优势:
- 没有浪费的 standby server, 所有 read replicas 都能用来做 failover 对象
- 副本和 master 之间在存储层同步, DDL 不会导致 read replica 的同步延迟,
- 磁盘空间每 10GB 自动增长, 最多 64TB, 只收一份的钱(rds 的 read replica 磁盘要另收费).
如果开启了 aurora 的 lab mode(通过 parameter group), aurora 还有几个实验性 feature. 比较有意思的是 fast DDL, MySQL 原始的 DDL, 需要拷贝整张表, 非常慢, fast DDL 可以在 0.x 秒内完成, DDL 过程中只会修改 information_schema, 并将老的表结构存进一张新的系统表中, 后续的 DML 会检查当前修改的 data page 是否有 pending 的 schema change 操作(通过比较 LSN), 需要的话就将 该 page 修改成新的结构, 然后再执行 DML.
类似一种 Copy-On-Write 的方式. 但这个功能目前只对添加不带 default value,nullable 的列,并且列加在表的最后的操作有效.
要注意的地方:
- aurora 只支持 InnoDB 存储引擎
- aurora 价格 = db instance + disk cost + io cost (02.$/每百万io)
- aurora provision 的磁盘空间按你数据库曾今达到的最大值算, 如果 drop 掉表,计费的空间不会减少, 后续新数据可以重用这部分空间. 所以如果在 aurora 上跑会生成很大的临时表的 ETL 要注意.
- 官方号称 aurora 的性能是 rds MySQL 的 5倍, 但从 percona 的文章和 quora 的这个回答看, 如果你的工作负载写大于读, 且写的表上有non unique 的二级索引的话, aurora 性能还不如 MySQL.
- disk size 能自动扩展, 但如果你删除数据库中的数据,空出的空间并不能立刻被复用,必须达到某个内部阈值这部分空间才能被重用(这个阈值文档里没有说明).
参考:
- https://aws.amazon.com/cn/blogs/database/amazon-rds-under-the-hood-multi-az/
- https://www.allthingsdistributed.com/files/p1041-verbitski.pdf
- https://www.percona.com/blog/2018/07/17/when-should-i-use-amazon-aurora-and-when-should-i-use-rds-mysql/
- https://aws.amazon.com/blogs/database/amazon-aurora-under-the-hood-fast-ddl/