最近在看 google 的 <The Site Reliablity Workbook>, 其中有一章是"Manage load", 内容还挺详细的, 结合在 aws 上的经验做点笔记.
Load Balancing
流量的入口是负载均衡, 最最简单的做法是在 DNS 上做 round robin, 但这样很依赖 client, 不同的 client 可能不完全遵守 DNS 的 TTL, 当地的 ISP 也会有缓存.
google 用 anycast 技术在自己的网络中通过 BGP 给一个域名发布多个 endpoint, 共享一个 vip(virtual ip), 通过 BGP routing 来将用户的数据包发送到最近的 frontend server, 以此来减少 latency.
但只依赖 BGP 会带来两个问题:
- 某个地区的用户过多会给最近的 frontend server 带来过高的负载
- ISP 的 BGP 路由会重计算, 当 BGP routing 变化后, 进行中的 tcp connection 会被 reset(同一个 connection 上的后续数据包被发送到不同的 server, tcp session 不存在于新 server 上)
为了解决原生 BGP anycast 的问题, google 开发了 Maglev, 即使路由发生了变化(routing flap), connection 也不断开, 把这种方式叫做 stablized anycast.
Maglev 是一个三层负载均衡, 管理着集群的入口流量, 放置在数据中心的 Router 后面.
每台 Maglev 可以将 client 端 ip 和离它最近的 google frontend server 映射起来, 如果 Maglev A 收到一个 client 数据包, 发现有比自己离用户更近的更近的 Maglev B, 就会讲数据包转发给 B (可能是由 ISP 的 BGP flap 造成的). Maglev B 收到数据包后转发给本地的 frontend server.
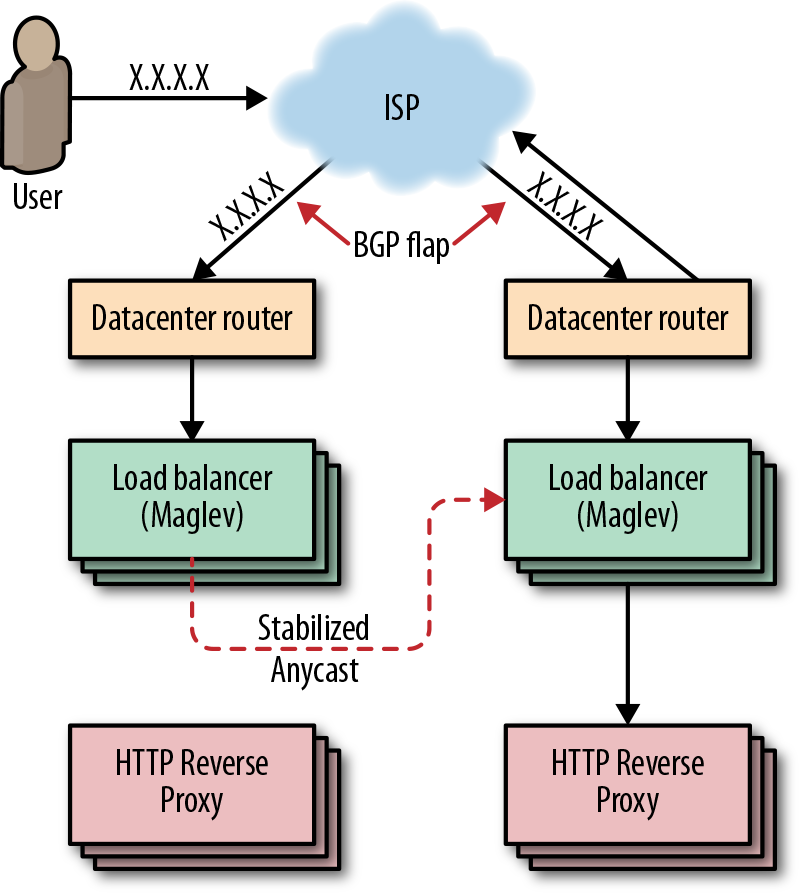
传统的 tcp 负载均衡方案可能是主备的, 提供的冗余是 1+1, 由于每台 Maglev 都有数据包的路由信息所以每台都是对等的, Maglev 提供了 1+N 的冗余, 扩容只需直接增加 Maglev 的个数就行.
Maglev 的容量规划按照处理的 packet 数目来定, 而不是传统 tcp 负载均衡的 connection 数目, 实现关键是一致性 hash + connection tracking.
Router 收到数据包后转发给任意一台 Maglev (对等), Maglev 根据 packet 的 5 元组(source ip, port, dst ip, port, protocol type)计算 hash, 根据 hash 值在 connection tracking table 中寻找最近的 connection, 如果找到了,并且对应的 backend 还是 health 状态就重用 connection, 否则通过一致性 hash 重新寻找一个 backend.
放在 Maglev 后面的 http reverse proxy 是 GFE (google front end), 类似 nginx, 用来做业务层路由, ssl termination, backend health check.
GSLB (global software load balancer) 充当各层之间的胶水, maglev 找最近的 GFE, GFE 找最近的 backend 都是通过 GSLB.
GCLB (google cloud load balancing) 基于以上技术栈构建提供给 gce 用户的负载均衡方案. 用户创建 gclb 的时候, 会创建一个 vip, 并通知 Maglev, 来将发送到这个 vip 的数据包转发到最近的 GFE, GFE 再转发到用户的 backend service.
相比较而言 AWS 的 ELB, ALB, NLB, 就传统多了, 没有 Maglev 这么潮,也不提供跨 region 的负载均衡能力.
Pokemon Go 的扩容例子
书里拿 Niantic 的 Pokemon Go 在 GCE 上的扩容做了个例子,来解释这套技术栈的应用.
Pokemon Go 上线前, 他们预估的 traffic 是 X, 压测时候保证了他们的 infra 能在 5X 的负载之下工作. 可实际流量远超预期, 达到了 50X.
在 Pokemon Go 刚 launch 的时候, 负载均衡用的是 GCE 的 NLB, 和 AWS 的 NLB 一样是个 region only 的 4 层负载均衡, 挂在 NLB 后面其实就是挂在了 Maglev 后面. Niantic 的 cluster 是 kubernetes, 结构如下图:
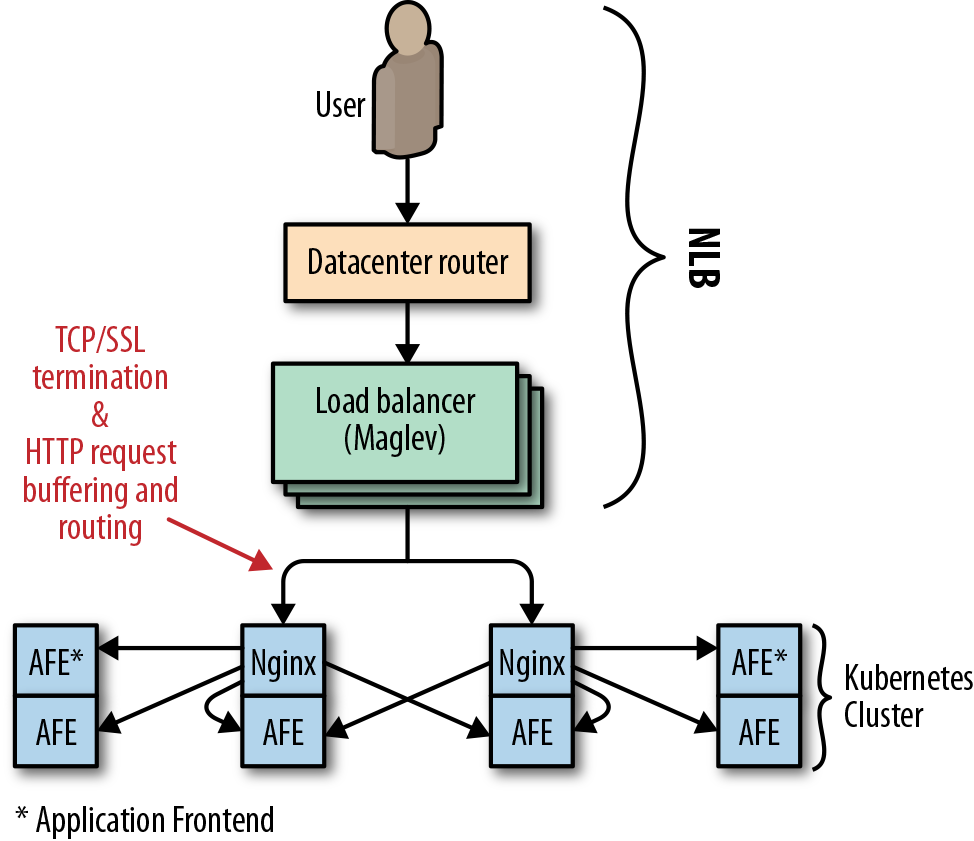
有如下问题:
- NLB (Maglev) 是在 ip 层做负载均衡, 无法阻止 SYN flood 攻击.
- SSL termination 由 Niantic 的 nginx 来完成, 这就多了一跳.
- nginx 会做 request buffer, 由于 Niantic 的 client 都是 mobile, 链接不稳定, 大量的 slow request 很快地耗完了 nginx 的系统资源.
于是 Niantic 转向了 GCLB, 但在迁移过程中对容量估计还是不够, 峰值时候的流量比迁移前观测的高了2倍, 直接达到了 Niantic 的容量 quote. 太高的流量让大量 向 backend server 的 request 失败, load balancer 的重试机制加剧了系统压力, GFE 的 SSL 解密模块直接过载了, 导致了 GCLB 在全球范围内性能降低了 50%. 看样子 GCLB 默认情况下是不做租户隔离的.
Pokemon Go 的 app 在同步失败后会间隔一段固定时间进行重试, 这又给 server 带来的很高的瞬间压力, google 之后专门给 Pokemon Go 的 GCLB 做了隔离, 并扩容. Niantic 那侧将 client 端的重试算法改成了指数补偿式的, 并加入随机偏移量, 避免瞬时高峰.
Auto Scaling
auto scaling 这章和我在 AWS 上的使用经验差不多, 有一些要注意的:
- 一般 scale out 的时机是按照 cpu 计算的, 注意留好 buffer, 新 instance 进入工作状态需要时间.
- 设置好合理的 max, min size, 如果因为意外导致不停得起新 instance 或 shutdown, 不至于让 live 进入一个死循环.
- aws 的 autoscaling group 只能简单得按照 cpu 值做 scale, 有一个潜在风险, server 在启动过程中需要做一些 provision, 如果中途挂了, 但 server 状态是 active, 此时 server 不是 up 状态, 用户流量不会过来, 但 autoscaling group 算 load 的时候仍旧把这台没工作的 server 算进去了, 拉低了整体 cpu 数值, 会导致后续的 scale out 延迟. 这种情况比较少, 目前我没有自动化处理, 直接干掉那台 server 重新 provision 一台, 最好能有办法在 service 真正 up 再之后通知 autoscaling group 把它纳入计算.
References: