成功的经验总是带有点运气成份, 失败则是必然的:). 工作中, 线上环境的问题千奇百怪, 有的来自自己代码 bug, 有的是配置错误, 有时候是第三方的 vendor 成了猪队友. 对于一些排查过程比较困难或具有代表性的问题, 需要记录下来, 一般把这个过程叫做 postmortem(验尸).
这篇写一下自己做 postmortem 的过程, 并记录一个最近处理的故障.
Postmortem process
我大体分以下几个部分:
- 用尽量简练的语句描述清楚在什么时间发生了什么,谁参与了问题的处理(when, what, who)?
- 详细描述解决问题的过程, 包括但不限于: debug 的过程, 中间的推测, 用到的工具… (How)
- 如果找到了 root case, 记录下来, 没找到, 记录下当时的 workaround, 有什么副作用. (Why)
Postmortem case
实际的 postmorten 写得更简单一点, 这里把过程中的一些思考也记下来.
when, what, who
在 2020/01/13 23:18(UTC+8), 收到 xx service latency 异常报警. Assign: XX(me)
How
只有这一个 service 出现 latency 异常, 其他都正常, 要么是该 service 更新了什么代码导致,要么是它依赖并独享的某个组件出了问题.
快速扫一眼 deployment history, service 上次代码部署是三天前, 内容只改了几个显示给用户看的文字, 排除是新代码上线导致的.
该 service 独享的组件有: DynamoDB 里的几张 table, 一个单独的 MySQL RDS 实例, 用作消息队列 broker 的 redis. redis 挂了会立刻有报警, 且 sentry 的 slack channel 里会报大量相关 exception, 并没有.
查看 RDS 的监控, iops 有异常:
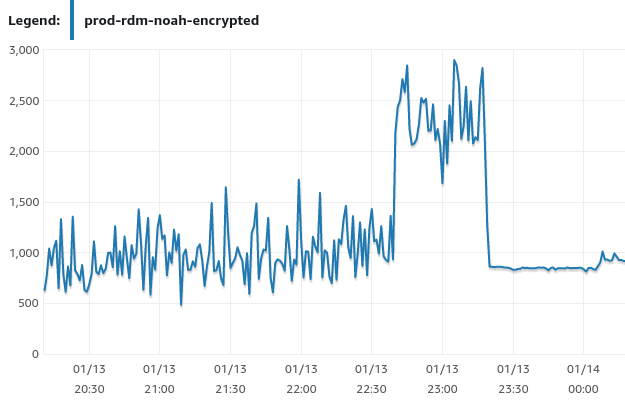
该实例使用 gp2 类型的 ebs 作为 storage, gp2 类型 ebs 的 iops = size in GiB * 3, size = 300, 所以 baseline iops 是 900, 同时 gp2 类型有 io credit, 可以在短时间内 burst 到 3000 iops,可持续时间大概是 30 mins.从图上看 22:40 分的时候, iops bump 到了接近 3000, 此时已经开始消耗 io credit 了, 但 latency 还是正常的, 在 23:18, io credit 消耗完, iops 就被限制在了 baseline 900, 这时触发了 latency 报警.
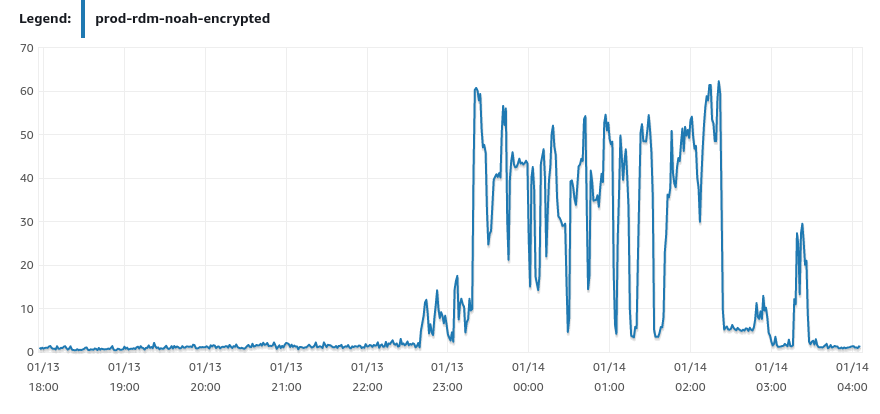
此时也收到了该 RDS 实例 queue depth 太高的报警, 因为 prometheus 是从 cloudwatch poll 的数据, rds 的 queue depth 数据有几分钟的延迟.
查看 RDS queue depth 监控, queue depth 的确很高了.:
查看 aws 的 status page, 并没有 RDS 相关的故障报告(这个 status page 并不是很靠谱, 如果非常确定锅在 aws, 直接提 ticket, 或上 twitter 搜下有没有人抱怨更准确点, 我把这个叫 social media monitoring…)
查看 grafana 上的监控.
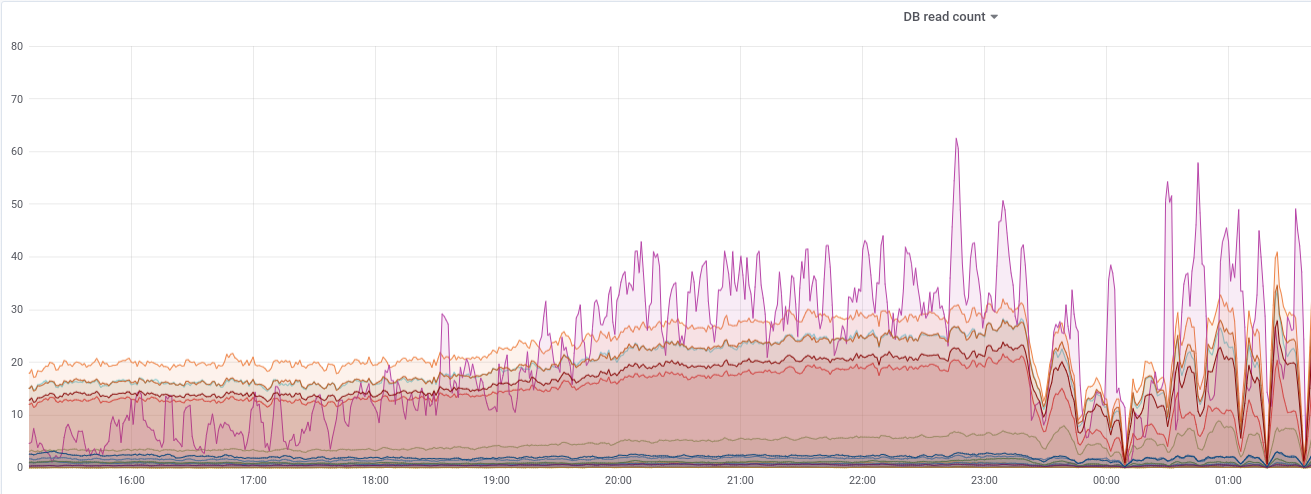
这张图里的 metrics 是业务代码里记下来的, 表示对 db 里每张表的 read count 计数.
很明显看到粉色的区域最近几小时读取异常高. 看了下业务代码里对应表的操作逻辑,没有 cache, 相关代码应该很久没有动过了, 暂时不清楚 read 是哪来的.
当时的 workaround:
- 改代码给那张表加 cache.
- 升级数据库, 暂时把 ebs 改成 provisioned iops storage.
我选择了2, 因为时间是凌晨了, 精神状态也不好, 一般要避免在处理故障的时候改动逻辑复杂的代码, 假如我加了 cache, 就要正确处理 invalid cache 的逻辑, 没和熟悉这段业务逻辑的人协商的话, 不要做这种改动.
直接在 aws console 上把 storage type 改成 3000 iops 的 provisioned iops ebs.
但这个过程是比较慢的, 尤其那个时间点美国的活跃用户不少, 总过程花了差不多 3 小时, 在过程中用户端会间歇性看到 timeout. 同时为了减少对 db 的读, 临时关闭了消息队列, 副作用是用户会暂时收不到推送.
RDS 的变更完成后 latency 立刻恢复正常, 当然 iops 和往常比还是高很多.
Why
导致 latency alerting 的直接原因是 xx table read 过高, root case 暂时未知, workaround 是临时提高 db iops.
第二天和同事讨论了一下, 发现导致 db read 过多的原因是前几天发了一个 client 版本(灰度发布的, 头几天看不出来), 有一个逻辑会导致用户全量 pull 某种数据, 这就是那张表的 read 来源.
后续处理:
- 给那张表加上 cache.
- 把 client 的 release 周期也放进监控流程.
- 把 ebs type 改回 gp2(provisioned iops 会增加每月大概 600$ 的 cost)