patroni 的安装跳过, 它只是个 python 包, 把依赖装好就行, 同时要求装好 postgres-server, patroni 运行过程中会调用 pg_ctl 等命令: https://patroni.readthedocs.io/en/latest/README.html 每个 patroni 管理一个 pg 实例, 两者必须部署在同一节点上, patroni 需要能:
- 访问 pg 的监听端口
- 读写 pg data dir (patroni 会重写 postgres.conf, pg_hba.conf 等文件)
配置文件
配置文件是yaml 格式, 具体见 https://patroni.readthedocs.io/en/latest/SETTINGS.html
使用 patroni postgres.yaml 命令启动一个 patroni 实例
# 集群名字, 同一集群内的 patroni 必须设置一样, 会成为 postgres.conf 内的 cluster_name参数
scope: xsky-test
# patroni 会将一些动态配置存在 DCS 内, namespace 是在 DCS 内的存储路径, eg: 使用 etcdv3 作为 DCS, 可以通过 etdctl get /service --prefix 看到 patroni 在 DCS 内存了什么
namespace: /service
# 管理的 pg 的实例名, 同一集群内每个实例必须都不同, eg: pg0, pg1, pg2
name: pg0
# 日志相关配置
log:
level: INFO
...
# patroni restapi 相关配置
restapi:
listen: 0.0.0.0:8008
...
# 用创建 pg 实例, 生成 pg 的 data dir, postgres.conf, pg_hba.conf 等文件
bootstrap:
# dcs 下内容会写入 DCS 的 {namespace}/{scope}/config key 中,只有在初始化集群的时候被使用一次, 后续修改不会生效, 可以通过 patrionctl edit-config 或 rest api 来修改存在 dcs 中的值
dcs:
loop_wait: 10
ttl: 30
...
# 初始化集群时生成 pg_bha.conf, 后续改动不会生效
pg_hba:
- host replication replicator 127.0.0.1/32 md5
# 在初始化集群时需要创建的用户, 后续改动不会生效
users:
...
# 使用 etcd v2 api 作为 dcs
etcd:
...
# 使用 etcd v3 api 作为 dcs
etcd3:
...
# 用于 patroni 运行时连接 pg
postgresql:
listen: 0.0.0.0:5432
...
# patronictl.py 连接 restapi 时 http参数(ssl相关)
ctl:
...
# 通过 linux 的 softdog 模块, 在 patroni 控制的 pg 挂掉时重启 server
watchdog:
...
# 通过nofailover 等 tag 可以控制行为(eg: 不允许某个 patrion 实例成为 leader, 也可以添加自定义tag作为元数据
tags:
...
用 patroni bootstrap pg 集群
假设有三节点, 上面已经部署好 etcd(v3) 作为 dcs, 三节点 ip为: 10.252.90.217, 10.252.90.218, 10.252.90.219 217 节点上 patroni 的 postgres.yml 配置, 其他节点类似, 把 ip 改下:
scope: xsky-test
name: pg0
log:
level: DEBUG
restapi:
listen: 0.0.0.0:8008
# 必须设置成非 loopback 地址, 这个地址会存在 etcd 中, 其他 patroni 节点会从 etcd 中获取后连接该节点
connect_address: 10.252.90.217:8008
etcd3:
hosts:
- 10.252.90.217:2379
- 10.252.90.218:2379
- 10.252.90.219:2379
bootstrap:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 10
postgresql:
# 当 failover 发生后, old leader 需要成为 new leader 的replica, 设置 true, 就会通过 pg_rewind 来同步 offset, 否则会用 pg_basebackup 全量重建备库
use_pg_rewind: true
# 开启后会同步 pg 的 replication slots(通过 db conn)
use_slots: true
# 启用 pg 的同步赋值模式, 后面演示脑裂状态时会用到
parameters:
synchronous_commit: "on"
synchronous_standby_names: "*"
initdb:
- encoding: UTF8
- data-checksums
pg_hba:
# 允许其他节点的 replicator 用户连接过来进行日志同步
- host replication replicator 0.0.0.0/0 md5
# 允许常规 db 连接
- host all all 0.0.0.0/0 md5
postgresql:
listen: 0.0.0.0:5432
connect_address: 10.252.90.217:5432
data_dir: data/postgresql0
pgpass: /tmp/pgpass0
初始化第一个节点
patroni 会调用 pg_ctl 初始化数据库, pg 不能以 root 用户跑(pg 的限制), 所以新建个 user, 用 su 切过去 来跑下面的命令
patroni postgres.yml
想查看 patroni 初始化过程具体干了啥可以, 安装 bcc-tools, 用里面的 execsnoop 工具追踪 patroni 的shell 调用:
[root@node-217 tools]# execsnoop -U
UID PCOMM PID PPID RET ARGS
1000 python3 27506 27057 0 /usr/bin/python3 patroni.py postgres0.yml
1000 sh 27507 27506 0 /bin/sh -c uname -p 2> /dev/null
1000 uname 27508 27507 0 /usr/bin/uname -p
1000 ldconfig 27509 27506 0 /sbin/ldconfig -p
# 调用 pg_ctl 初始化数据库--encoding=UTF8 --data-checksums 是配置文件中 initdb 项传入
1000 pg_ctl 27516 27506 0 /usr/bin/pg_ctl initdb -D data/postgresql0 -o --encoding=UTF8 --data-checksums --username=postgres --pwfile=/tmp/tmp68bda8l8
1000 sh 27517 27516 0 "/usr/bin/initdb" -V
1000 initdb 27517 27516 0 /usr/bin/initdb -V
1000 sh 27518 27516 0 "/usr/bin/initdb" -D "data/postgresql0" --encoding=UTF8 --data-checksums --username=postgres --pwfile=/tmp/tmp68bda8l8
1000 initdb 27518 27516 0 /usr/bin/initdb -D data/postgresql0 --encoding=UTF8 --data-checksums --username=postgres --pwfile=/tmp/tmp68bda8l8
1000 sh 27519 27518 0 "/usr/bin/postgres" -V
1000 postgres 27519 27518 0 /usr/bin/postgres -V
1000 sh 27520 27518 0 "/usr/bin/postgres" --boot -x0 -F -c max_connections=100 -c shared_buffers=1000 -c dynamic_shared_memory_type=none < "/dev/null"
1000 postgres 27521 27520 0 /usr/bin/postgres --boot -x0 -F -c max_connections=100 -c shared_buffers=1000 -c dynamic_shared_memory_type=none
1000 sh 27522 27518 0 "/usr/bin/postgres" --boot -x0 -F -c max_connections=100 -c shared_buffers=16384 -c dynamic_shared_memory_type=none < "/dev/null
1000 postgres 27523 27522 0 /usr/bin/postgres --boot -x0 -F -c max_connections=100 -c shared_buffers=16384 -c dynamic_shared_memory_type=none
1000 sh 27524 27518 0 "/usr/bin/postgres" --boot -x1 -k -F
1000 postgres 27524 27518 0 /usr/bin/postgres --boot -x1 -k -F
1000 sh 27525 27518 0 "/usr/bin/postgres" --single -F -O -j -c search_path=pg_catalog -c exit_on_error=true template1 >/dev/null
1000 postgres 27526 27525 0 /usr/bin/postgres --single -F -O -j -c search_path=pg_catalog -c exit_on_error=true template1
1000 sh 27527 27526 0
1000 locale 27527 27526 0 /usr/bin/locale -a
# 到上一行为止都是 pg_ctl initdb 过程中做的事
# pg_controldata 命令用于从data目录获取数据库信息
1000 pg_controldata 27529 27506 0 /usr/bin/pg_controldata data/postgresql0
1000 python3 27530 27506 0 /usr/bin/python3 -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=0, pipe_handle=11) --multiprocessing-fork
1000 sh 27531 27530 0 /bin/sh -c uname -p 2> /dev/null
1000 uname 27532 27531 0 /usr/bin/uname -p
# 启动 pg 进程
1000 postgres 27533 27530 0 /usr/bin/postgres -D data/postgresql0 --config-file=/home/will/patroni/data/postgresql0/postgresql.conf --listen_addresses=0.0.0.0 --port=5432 --cluster_name=xsky-test --wal_level=replica --hot_standby=on --max_connections=100 --max_wal_senders=10 --max_prepared_transactions=0 --max_locks_per_transaction=64 --track_commit_timestamp=off --max_replication_slots=10 --max_worker_processes=8 --wal_log_hints=on
# 等待 pg server ready
1000 pg_isready 27536 27506 0 /usr/bin/pg_isready -p 5432 -d postgres -h localhost -U postgres
1000 pg_isready 27544 27506 0 /usr/bin/pg_isready -p 5432 -d postgres -h localhost -U postgres
1000 pg_controldata 27548 27506 0 /usr/bin/pg_controldata data/postgresql0
1000 pg_controldata 27549 27506 0 /usr/bin/pg_controldata data/postgresql0
查看 patroni 在 etcd 中写入了什么内容
etcdctl get /service --prefix
# 该key 由配置文件中的 bootstrap.dcs 一节构成,可以通过 patronictl edit-config 命令修改
/service/xsky-test/config
{"ttl":30,"loop_wait":10,"retry_timeout":10,"maximum_lag_on_failover":1048576,"postgresql":{"use_pg_rewind":true,"use_slots":true,"parameters":null}}
# db 初始化完成后写入该key, 值是通过 pg_controldata 命令获取的`Database system identifier` 字段
/service/xsky-test/initialize
7054455725282492035
# 第一个节点抢到主, 写入自己的 name, 这个key会绑定一个 lease(default: 30s),
# patroni 存活期间每隔 loop_time(10s) 会刷新下这个 lease
/service/xsky-test/leader
pg0
# members 路径下是当前集群所有成员
/service/xsky-test/members/pg0
{"conn_url":"postgres://10.252.90.217:5432/postgres","api_url":"http://10.252.90.217:8008/patroni","state":"running","role":"master","version":"2.1.2","xlog_location":24988528,"timeline":1}
# status 的值是当前 leader 的 wal lsn write location, 通过`select pg_current_wal_lsn()` 确认
/service/xsky-test/status
{"optime":24988528}
加入第二个节点
在 218 节点上执行
patroni postgres.yml
exesnoop 观察:
[root@node-218 tools]# execsnoop -U
UID PCOMM PID PPID RET ARGS
1000 python3 237755 237631 0 /usr/bin/python3 patroni.py postgres1.yml
1000 sh 237756 237755 0 /bin/sh -c uname -p 2> /dev/null
1000 uname 237757 237756 0 /usr/bin/uname -p
1000 ldconfig 237758 237755 0 /sbin/ldconfig -p
# 通过 pg_basebackup 从当前 leader 节点上复制数据库到 data 目录
1000 pg_basebackup 237765 237755 0 /usr/bin/pg_basebackup --pgdata=data/postgresql1 -X stream --dbname=dbname=postgres user=replicator host=10.252.90.217 port=5432 --verbose --max-rate=100M
1000 pg_controldata 237767 237755 0 /usr/bin/pg_controldata data/postgresql1
1000 python3 237768 237755 0 /usr/bin/python3 -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=0, pipe_handle=11) --multiprocessing-fork
1000 sh 237769 237768 0 /bin/sh -c uname -p 2> /dev/null
1000 uname 237770 237769 0 /usr/bin/uname -p
# 启动 replica server 进程
1000 postgres 237771 237768 0 /usr/bin/postgres -D data/postgresql1 --config-file=/home/will/patroni/data/postgresql1/postgresql.conf --listen_addresses=0.0.0.0 --port=5432 --cluster_name=xsky-test --wal_level=replica --hot_standby=on --max_connections=100 --max_wal_senders=10 --max_prepared_transactions=0 --max_locks_per_transaction=64 --track_commit_timestamp=off --max_replication_slots=10 --max_worker_processes=8 --wal_log_hints=on
# 等待 server ready
1000 pg_isready 237774 237755 0 /usr/bin/pg_isready -p 5432 -d postgres -h localhost -U postgres
1000 pg_isready 237780 237755 0 /usr/bin/pg_isready -p 5432 -d postgres -h localhost -U postgres
1000 pg_controldata 237782 237755 0 /usr/bin/pg_controldata data/postgresql1
查看replica 节点加入后, etcd 内变多了什么, 主要是下面两个 key
# 该 key 是 leader 节点的 pg_wal/xxx.history 文件内容, 每发生一次 failover, timeline就+1, 追加一条新 history, 可以通过 patronictl.py history 命令读取
/service/xsky-test/history
[[1,24988864,"no recovery target specified","2022-01-18T16:32:51.891714+08:00","pg0"]]
# 新加入节点信息, role 是 replica
/service/xsky-test/members/pg1
{"conn_url":"postgres://10.252.90.218:5432/postgres","api_url":"http://10.252.90.218:8008/patroni","state":"running","role":"replica","version":"2.1.2","xlog_location":83886400,"timeline":2}
同时, patroni 会在第二个节点上生成 recovery.conf
# Do not edit this file manually!
# It will be overwritten by Patroni!
primary_conninfo = 'user=replicator passfile=/tmp/pgpass1 host=10.252.90.217 port=5432 sslmode=prefer application_name=pg1'
primary_slot_name = 'pg1'
recovery_target_timeline = 'latest'
standby_mode = 'on'
在第三个节点上启动patroni 加入集群过程类似
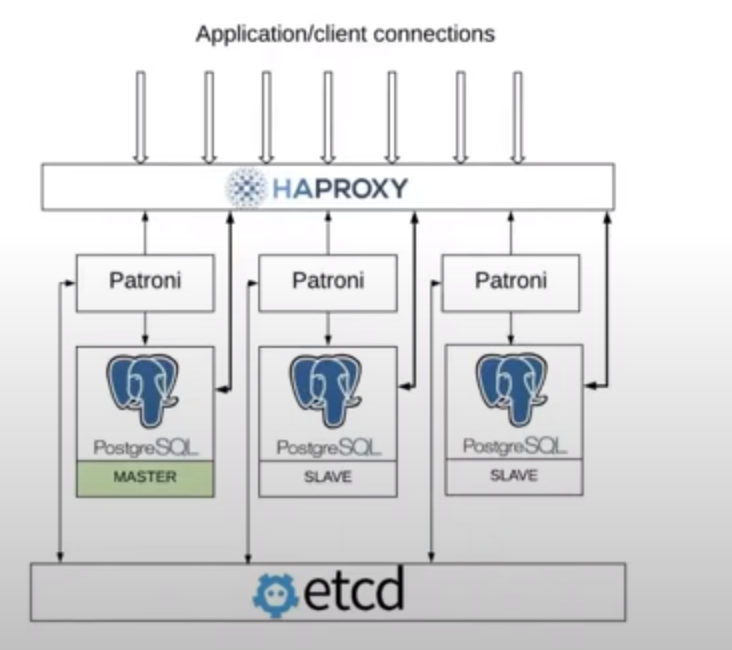
配置HAProxy
listen cluster-a-leader
bind *:5000
option httpchk OPTIONS /master
http-check expect status 200
default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions
server pg0 dev0:5432 maxconn 100 check port 8008
server pg1 dev1:5432 maxconn 100 check port 8008
server pg2 dev2:5432 maxconn 100 check port 8008
listen cluster-a-replicas
bind *:5001
option httpchk OPTIONS /replica
http-check expect status 200
default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions
server pg0 dev0:5432 maxconn 100 check port 8008
server pg1 dev1:5432 maxconn 100 check port 8008
server pg2 dev2:5432 maxconn 100 check port 8008
cluster-a-leader 指向当前的 leader pg, haproxy 检查后端三节点的 :8008/master 接口 (patroni api port), 返回200 表示该节点目前是 leader, replica 会返回 503. cluster-a-replicas 会指向 replica pg, :8008/replica 返回 200, leader 节点返回503.
手动触发 failover
先查看当前集群情况, 在任意一个节点上执行(现在假设在217上跑)
patronictl topology
+ Cluster: xsky-test (7054455725282492035) -------+----+-----------+----------------------------+
| Member | Host | Role | State | TL | Lag in MB | Tags |
+--------+--------------------+---------+---------+----+-----------+----------------------------+
| pg0 | 10.252.90.217:5432 | Leader | running | 2 | | |
| + pg1 | 10.252.90.218:5432 | Replica | running | 2 | 0 | |
| + pg2 | 10.252.90.219:5434 | Replica | running | 2 | 0 | {replicatefrom: postgres1} |
+--------+--------------------+---------+---------+----+-----------+----------------------------+
手工触发 failover
[will@node-217 patroni]$ patronictl failover
Candidate ['pg1', 'pg2'] []: pg1
Current cluster topology
+ Cluster: xsky-test (7054455725282492035) -------+----+-----------+--------------------------+
| Member | Host | Role | State | TL | Lag in MB | Tags |
+--------+--------------------+---------+---------+----+-----------+--------------------------+
| pg0 | 10.252.90.217:5432 | Leader | running | 5 | | |
| pg1 | 10.252.90.218:5432 | Replica | running | 5 | 0 | |
| pg2 | 10.252.90.219:5434 | Replica | running | 5 | 0 | replicatefrom: postgres1 |
+--------+--------------------+---------+---------+----+-----------+--------------------------+
Are you sure you want to failover cluster xsky-test, demoting current master pg0? [y/N]: y
2022-01-18 17:56:02.04583 Successfully failed over to "pg1"
+ Cluster: xsky-test (7054455725282492035) -------+----+-----------+--------------------------+
| Member | Host | Role | State | TL | Lag in MB | Tags |
+--------+--------------------+---------+---------+----+-----------+--------------------------+
| pg0 | 10.252.90.217:5432 | Replica | stopped | | unknown | |
| pg1 | 10.252.90.218:5432 | Leader | running | 5 | | |
| pg2 | 10.252.90.219:5434 | Replica | running | 5 | 0 | replicatefrom: postgres1 |
+--------+--------------------+---------+---------+----+-----------+--------------------------+
failover 命令运行过程中需要手工指定能提升为 leader 的 replica, 这里我们选择 pg1 运行完后 pg1 变成了 leader, pg0 变成 replica 看下三个节点各做了什么, 以下为设置 use_rewind 为 true 的情况下: new leader(pg1):
# 用 pg_ctl promote 提升为主
1000 pg_ctl 239361 239125 0 /usr/bin/pg_ctl promote -D data/postgresql1 -W
old leader(pg0):
# 用 pg_rewind 从 新 leader 取 diff 的 wal
1000 pg_rewind 31194 30785 0 /usr/bin/pg_rewind -D data/postgresql0 --source-server dbname=postgres user=postgres host=10.252.90.218 port=5432
1000 pg_controldata 31195 30785 0 /usr/bin/pg_controldata data/postgresql0
1000 pg_controldata 31197 30785 0 /usr/bin/pg_controldata data/postgresql0
# 启动 pg server
1000 postgres 31201 31198 0 /usr/bin/postgres -D data/postgresql0 --config-file=/home/will/patroni/data/postgresql0/postgresql.conf --listen_addresses=0.0.0.0 --port=5432 --cluster_name=xsky-test --wal_level=replica --hot_standby=on --max_connections=100 --max_wal_senders=10 --max_prepared_transactions=0 --max_locks_per_transaction=64 --track_commit_timestamp=off --max_replication_slots=10 --max_worker_processes=8 --wal_log_hints=on
1000 pg_isready 31208 30785 0 /usr/bin/pg_isready -p 5432 -d postgres -h localhost -U postgres
1000 pg_isready 31210 30785 0 /usr/bin/pg_isready -p 5432 -d postgres -h localhost -U postgres
pg2:
# 从 new leader(pg1) 处同步数据
1000 pg_rewind 242064 241235 0 /usr/bin/pg_rewind -D data/postgresql2 --source-server dbname=postgres user=postgres host=10.252.90.218 port=5432
1000 pg_controldata 242065 241235 0 /usr/bin/pg_controldata data/postgresql2
1000 pg_controldata 242067 241235 0 /usr/bin/pg_controldata data/postgresql2
1000 python3 242068 241235 0 /usr/bin/python3 -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=0, pipe_handle=11) --multiprocessing-fork
1000 sh 242069 242068 0 /bin/sh -c uname -p 2> /dev/null
1000 uname 242070 242069 0 /usr/bin/uname -p
# 启动 pg server
1000 postgres 242071 242068 0 /usr/bin/postgres -D data/postgresql2 --config-file=/home/will/patroni/data/postgresql2/postgresql.conf --listen_addresses=0.0.0.0 --port=5434 --cluster_name=xsky-test --wal_level=replica --hot_standby=on --max_connections=100 --max_wal_senders=10 --max_prepared_transactions=0 --max_locks_per_transaction=64 --track_commit_timestamp=off --max_replication_slots=10 --max_worker_processes=8 --wal_log_hints=on
1000 pg_isready 242078 241235 0 /usr/bin/pg_isready -p 5434 -d postgres -h localhost -U postgres
1000 pg_isready 242080 241235 0 /usr/bin/pg_isready -p 5434 -d postgres -h localhost -U postgres
测试 failover 过程中 db 可用性
#!/bin/bash
patronictl failover --master pg0 --candidate pg1 --force &
while [[ 1 ]]; do
echo `date`
psql -h localhost -p 5000 -U admin -t postgres -c 'insert into test1 values(1)'
sleep 0.5
done
Fri Jan 21 10:49:10 CST 2022
INSERT 0 1
Fri Jan 21 10:49:11 CST 2022
INSERT 0 1
Fri Jan 21 10:49:12 CST 2022
psql: server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
Fri Jan 21 10:49:15 CST 2022
ERROR: cannot execute INSERT in a read-only transaction
Fri Jan 21 10:49:16 CST 2022
ERROR: cannot execute INSERT in a read-only transaction
Fri Jan 21 10:49:17 CST 2022
ERROR: cannot execute INSERT in a read-only transaction
Fri Jan 21 10:49:18 CST 2022
INSERT 0 1
Fri Jan 21 10:49:19 CST 2022
INSERT 0 1
Fri Jan 21 10:49:20 CST 2022
INSERT 0 1
如何防止脑裂
假设当前 topology
[will@node-217 ~]$ patronictl topology
+ Cluster: xsky-test (7054740837533385088) --+----+-----------+----------------------------+
| Member | Host | Role | State | TL | Lag in MB | Tags |
+--------+---------------+---------+---------+----+-----------+----------------------------+
| pg0 | 10.252.90.217 | Leader | running | 8 | | |
| + pg1 | 10.252.90.218 | Replica | running | 8 | 0 | |
| + pg2 | 10.252.90.219 | Replica | running | 8 | 0 | {replicatefrom: postgres1} |
+--------+---------------+---------+---------+----+-----------+----------------------------+
关闭 leader pg
pg_ctl stop -D data/postgresql -m immediate
patroni 会把 pg 重新拉起:
- 耗时(postgres server 启动并通过 pg_isready 检查)在 ttl(默认30s) 之内, 不会发生 failover, 在此期间 replica 可读, leader 宕机
- 耗时在超过 ttl, etcd 内 key 就过期, 触发 failover, 后续 old leader 起来后, 变成新 leader 的replica
leader patroni 正常关闭
graceful shutdown 过程中 patroni 会关闭 pg0, 剩下的 pg1/2 进行抢主(实际两者会互相对比下 wal offset, 如果发现对方的比自己新, 会把锁让出来), 选出一个 leader. 此时无脑裂
leader patroni 异常关闭
kill -9 $(pgrep patroni) 模拟一下, 此时 pg0 上 postgres 进程还在(pg 并不会知道 patroni 的存在). etcd 中的 /service/xsky-test/leader key ttl 是30s, patroni 每隔10s会刷新一下 ttl, 所以该key 会在 20s~30s 之后失效, 此时 pg1/pg2 去抢主 等 pg1/2 完成选主, 此时集群中已经有两个 leader 了. 在 pg1 上执行查看当前 topology
+ Cluster: xsky-test (7054740837533385088) --+----+-----------+----------------------------+
| Member | Host | Role | State | TL | Lag in MB | Tags |
+--------+---------------+---------+---------+----+-----------+----------------------------+
| pg2 | 10.252.90.219 | Leader | running | 9 | | {replicatefrom: postgres1} |
| + pg1 | 10.252.90.218 | Replica | running | 9 | 0 | |
+--------+---------------+---------+---------+----+-----------+----------------------------+
pg2 成了主, 那原来 pg0 上的 postgres 就成了 orphan leader, 会发生脑裂, 怎么处理?
前面放置 haproxy 做代理
listen cluster-a-master
bind *:5011
option httpchk OPTIONS /master
http-check expect status 200
default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions
server postgresql_a1 127.0.0.1:6011 maxconn 100 check port 8008
server postgresql_a2 127.0.0.1:6012 maxconn 100 check port 8008
server postgresql_a3 127.0.0.1:6013 maxconn 100 check port 8008
ha proxy 把所有节点挂成 upstream, health check 的路径是 patroni 的 api, patroni 挂了, 就把 pg 从 upstream 里摘掉.
patroni 和 pg 放置在一个容器中
patroni 作为容器的 entrypoint, patroni 退出, 让 pg 也随着容器退出.
使用 linux 的 watchdog 机制
需要先配置好 watchdog, 然后 patroni 配置文件中设置 watchdog.required = true. 每次 patroni 在把一个 pg 实例 promote 成 leader 之前,会尝试先激活 watchdog, 如果失败, 则不会把该 pg 选为主, promote 成功后, patroni 定时往 /dev/watchdog 设备写入一个字节作为心跳(在 etcd 中 update leader key 成功后), 超过配置的时间没写入, 系统就会重启. 可能存在的问题:
- 我们把其他业务和 pg/patroni 跑在同一个节点上, 可能并不想当pg 失去 leader 或 patroni 挂了后整个 server 重启
- 在watchdog 重启系统之前还是有个时间间隔, client 还是能往 old leader 里写入成功
配置 postgres 使用同步复制
默认配置下, patroni 设置 postgres 使用异步复制, 此时 replica 节点和 leader 可能存在 lag, 可以设置maximum_lag_on_failover, 让 lag 超过阈值的 replica 不选成主. 如果切换成同步复制模式, leader 节点只有当 replica 节点也 commit 成功时, 才会返回给 client 说写入成功, 否则 hang 在那(不过其实 leader 本地已经 commit 成功了, client 超时重连的话, 能查到之前数据的).
PS: pg 的同步复制模式类似 MySQL 的半同步复制, 通过参数调整也可以模拟 MySQL 的全同步复制
pg 的同步复制模式
可以直接修改 postgresql.conf 开启同步复制的方式:
bootstrap:
dcs:
postgresql:
parameters:
// pg 的默认值就是on, 只是不配置synchronous_standby_names 的话不会生效
synchronous_commit: "on"
// * 表示任意一台, 即, 保证必须有一台 replica 在线, 否则 leader 节点会拒绝写入.
synchronous_standby_names: "*"
// synchronous_commit: remote_apply
同步复制的缺点是影响写入性能. 直接修改 postgresql.parameters 的方式缺点是我们没法知道哪台replica 是当前的 sync replica.
patroni 的 synchronous_mode 封装
patroni 把 postgresql.conf 中的 synchronous_standy_names 这个参数封装了一下, 由三个参数控制:
- bootstrap.dcs.synchronous_mode: true 这个参数必须设置为 true, 后续参数才会生效:
- 第一个连上的 replica 会被写入synchronous_standby_names(patronictl list 能看到它的Role 是 Standby Replica)
- 如果Standby Replica 断开连接, 其他存活的 replica 会接替成为 StandbyReplica, 更新 synchronous_standby_names
- 如果集群中没有可用 replica, synchronous_standy_ames 会是空, 保证 leader 仍旧可写
- bootstrap.dcs.synchronous_node_count 默认是1, 如果设置成2, 连上两台时 synchronous_standy_names 会被设置成 2 (pg1,pg2) 需要等pg1 commit, 然后 pg2 commit, leader 才会把写入成功的消息返回给 client
- bootstrap.dcs.synchronous_mode_strict: true, 控制当所有 replica 都不在线时 leader 的行为: 效果是会把 synchronous_standy_names 设置为 *, 即需要至少有一台 replica 在线, leader 节点会拒绝写入 如何选择:
- 性能 > 可用性 > 一致性 , 设置 synchronous_mode:false (默认情况)
- 可用性 > 一致性 > 性能 , 设置 synchronous_mode:true, synchronous_node_count: 1, 当所有replia离线, leader 还是能写入数据, 还是保证了可用性, 当前 Standby Replica 挂掉后, 大概需要10s 的时间切换到下一个 replica,在次期间, client 会hang住, 直到切换完成.
- 一致性 > 可用性 > 性能, 要求极致的一致性, synchronous_mode: true, synchronous_node_count: 2, synchronous_mode_strict: true, postgresql.parameters.synchronous_commit: remote_apply(等replica apply wal 之后 leader 才commit tx, 会非常大地影响性能), 场景是业务里做了读写分离, 并且完全不能接受 replica 和 leader 之间有LAG, 要求:
- 做了 failover 后 replica 一点数据都不丢数据
- 当 replica 都离线时, master 处于真正的 read only
比较均衡的设置:
- synchronous_mode: true, synchronous_node_count: 1, 这样一台 replica 的 wal 追得比较新
用 patroni 管理现有 pg 实例
先启动 pg 实例, 然后启动 patroni (指向 pg 的 data dir),patroni 会检测到 pg 已经启动, 但 pg 的配置文件和 patroni 中的可能不是同步的, 需要用 patronictl restart 命令重启节点来同步配置 不是很推荐这种做法, 使用 patroni 管理 pg 必然会 rewrite postgres.conf, 所以应该由 patroni 来做 pg 的起停管理.