市面上各种 agent 用过不少,cursor、claudecode、codex、opencode、trae、openclaw、pi……其实也没感觉哪个对其他有降维打击,反而各有各的不爽: 要么有模型限制,换别的兼容接口要各种转接,运行过程不透明——之前做了 linko,初衷也是为了搞清楚各种 agent 都在干嘛。 要么天天升级弄出各种奇怪 bug,要么过度臃肿,要配各种看着有用实际用起来又没什么卵用的插件。
所以,在 2026 年这个时间点,自己从 0 开始做一个 agent 到底有门槛吗(不限于 coding)?于是 4 月的时候开始做了 tachi。 结论是:做一个匹配个人需求和工作流的 agent,毫无门槛,有手就能干,效果不会比任何现有工具差。要做满足通用需求的 agent,有门槛,门槛主要在产品细节的打磨和各种适配——这些对个人使用其实毫无价值,偏偏又是通用工具里工程量最大的部分。
tachi 有任何比现有 agent 强的地方吗?没有。我没规划任何超过现有 agent 的功能,基本就是从各家抄了点功能,缝合成自己想要的样子。
需求:
- 部署简单
- 只满足自己的需求,不做无用的集成
- 极致的透明,方便 debug
TUI 模式
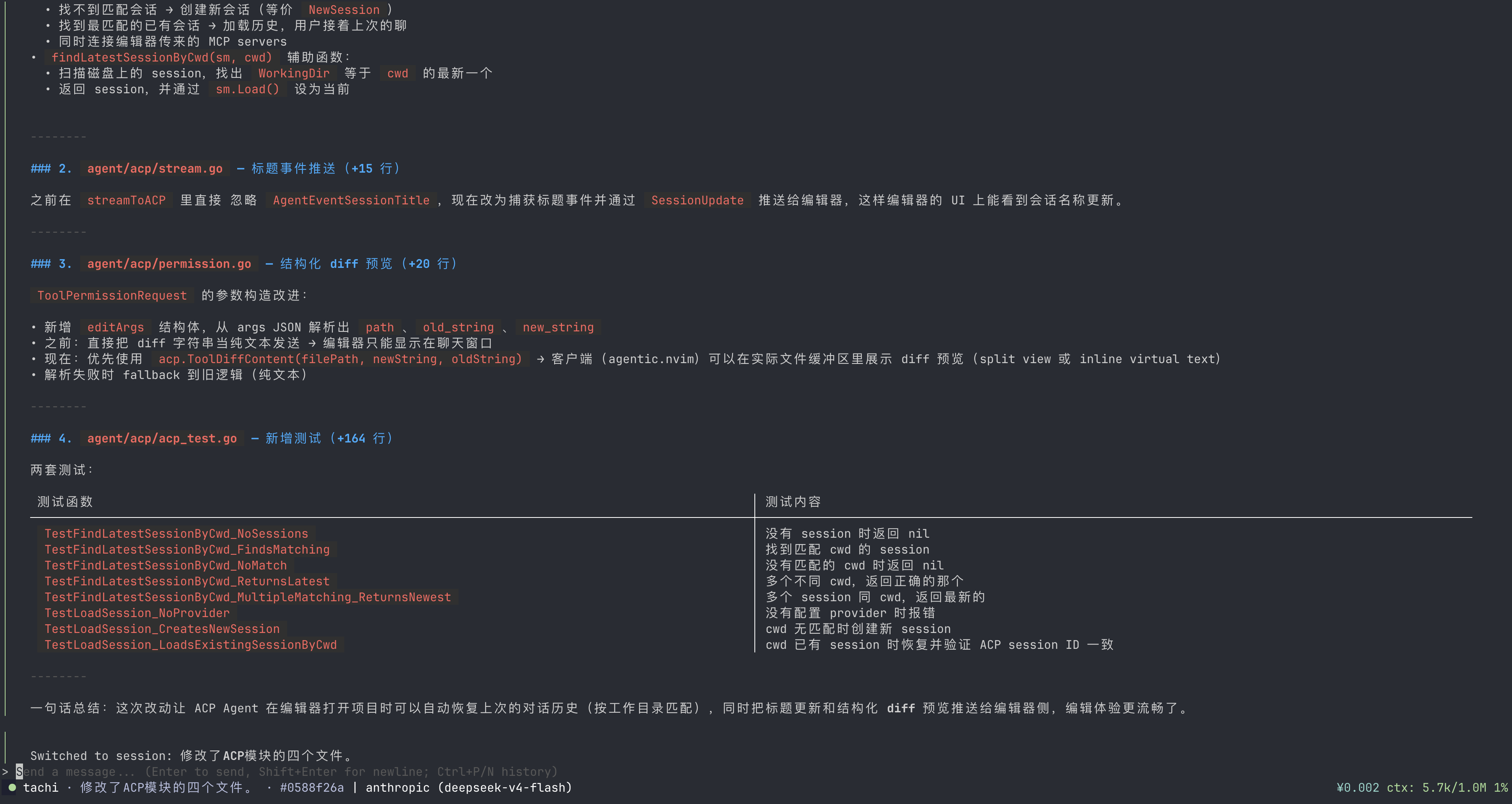
不需要花里胡哨的界面,只要输入框和 chat view,显示基本的模型信息和用量。
- 支持 @ 模糊搜索文件
- slash command
channel 模式

openclaw 对我唯一有用的功能,只支持了微信 channel。虽然微信和其他 IM 比,作为个人助理渠道是差劲了点,但凑合也能用——打开频率高于一切。(其实也支持了公司内部 IM,代码放内部仓库了,只在公司跑的版本接了。)
channel 运行模式下默认会开启 cron 功能,并挂载 CronTool,可以做定时任务,支持:
- one-shot 任务:定点执行完后自动删除
- recurring 任务:循环定时
- 条件静默:当 llm 判断不符合发送条件时,返回
[SILENT],跳过推送 - 支持向 tachi 发送文件让它分析,也可以让它把本地文件作为微信附件发送过来(只在 channel 模式下挂载 SendFile 工具)
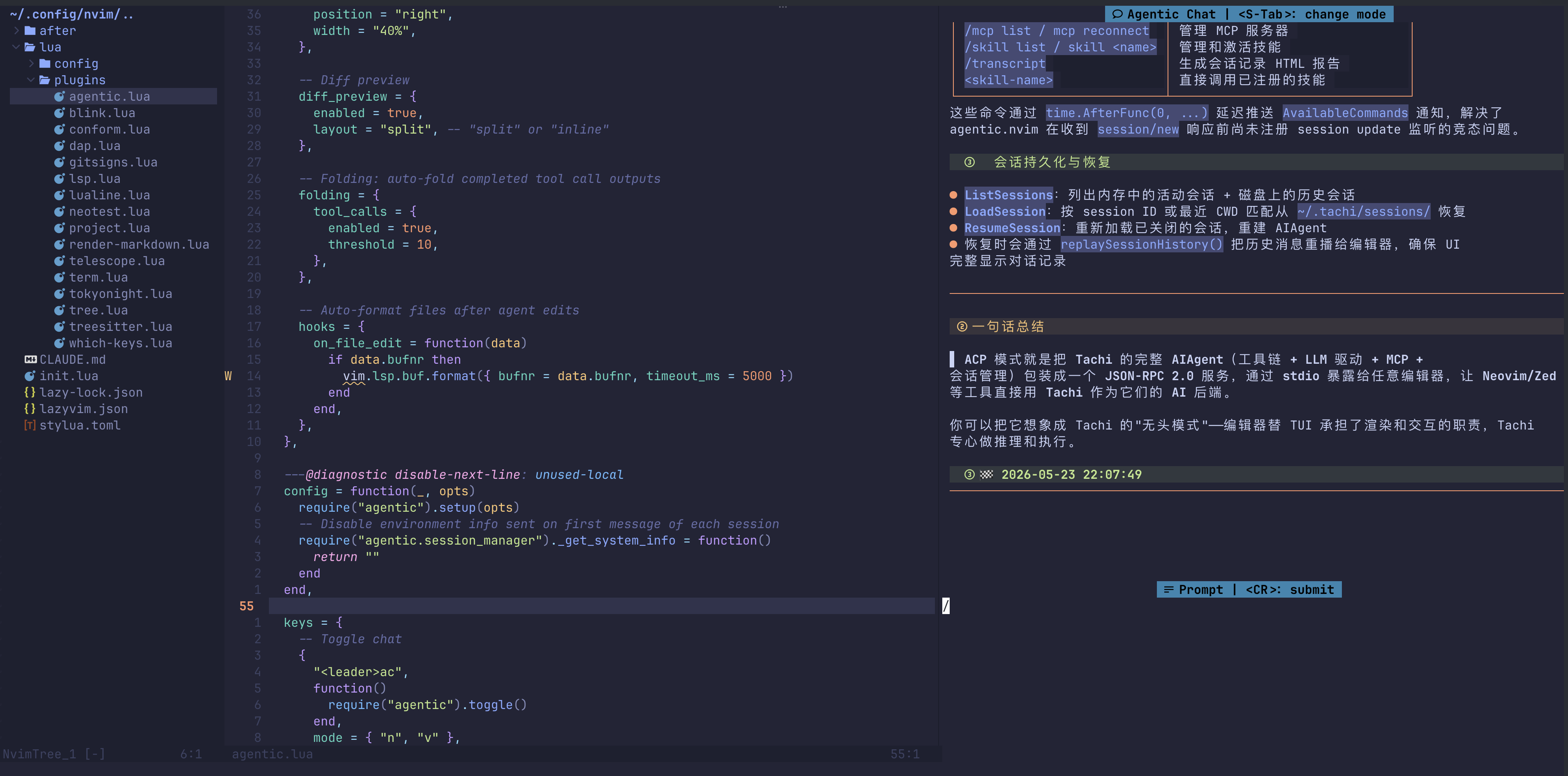
ACP 模式
实现了 ACP(Agent Client Protocol),可以作为 agent server 运行,被任何支持 ACP 的 Client 调用。
在 agentic.nvim 里的集成效果:
在 zed 里集成:
基本功能集
内置 tool
- Bash(支持后台执行和取消,没做危险命令检测)
- AskUserQuestion(向我提问,抄了 ClaudeCode)
- Cron(CRUD cron 任务,只在 channel 模式下运行)
- Edit / Glob / Grep / Write(代码编辑四件套)
- RecordMemory(主动记忆,记忆后端目前实验性支持了 mem9,但感觉没什么效果……)
- SendFile(在 channel 模式下向我发送文件)
- Skill(管理 skill)
- SubAgent(用 subagent 并行运行任务,支持 worktree 隔离,目前实现不继承 main agent 的上下文)
- WebFetch(下载网页并转换成 markdown 后发给 llm)
- WebSearch(支持 brave、serpapi、serper,日常薅 brave 的免费额度用着)
MCP Server
支持 stdio + http 的 MCP Server(也支持 MCP Server OAuth2 流程)。
额外支持了 MCP 工具的渐进式加载:首次 prompt 时,只发送 enable 的 MCP Server tool 的名字和描述,放在 <available-deferred-tools> 的 XML tag 内,并加载一个 MCPSearchTools 工具,让 llm 按需加载。在 defer pool 中的 MCP tool 不会在 HTTP 请求中发给 llm,只有当被 llm 通过 MCPSearchTools 发现后,才会发给 llm。(PS:这里特意根据 tool 的发现顺序维护了在 API 中的顺序,而不是按字母排序,为了不破坏 prompt cache。)
Skill
支持 project 和全局 scope 的 skill,可以通过内置的 Skill tool 动态创建。
skill 列表会在首次 prompt 中作为 <available-skills> tag 内容发送给 llm,被选中后渐进式加载。
transcript 导出
TUI、channel、ACP 模式下都可以通过 /transcript 命令以 HTML 格式导出当前会话的聊天历史,channel 模式下会作为附件直接发给我。
开发过程
上面写的其实都没什么看的意义(笑),因为压根没打算给别人用。README 里一开始写了配置方法,后来又删了——想想还是不要误人子弟了,随时会跟着自己需求魔改,而且从别人的角度看,tachi 并没有很特别的功能,纯粹是我的个人实验。放 GitHub 上其实是为了方便我在不同的机器上通过 Homebrew 安装和升级……
大约从 4 月中旬开始开发的,一开始用的是 claudecode + minimax2.7 + 少量 opus4.6。大约写到 5k 行左右的时候(去掉 UT 大概 3k),处于初步可用状态了(完成了 Edit、Write、Glob、Grep、Bash + 基本 TUI)。从 5k 到现在接近 4w 行,都是用 tachi 自己迭代的。也差不多这个时候,DeepSeek 发布了 v4 Pro/Flash。从那时起,代码基本都是用 DeepSeek v4 写的,大部分是 Pro,后面感觉 Flash 也差不多,速度还快,就都用 Flash 了。Token 消耗大概 8 亿(80% 应该都是 DeepSeek)。
大概的开发过程(中间混了无数轮重构):
- llm 封装(OpenAI + Anthropic)——说实话,我基本只用 Anthropic 兼容接口,OpenAI 的 chat completion 接口太烂了,都没怎么用过,我都想删了
- 基本 agent loop + tool call 抽象支持
- 完成 Edit、Write、Bash、Grep、Glob 工具(Grep、Glob 一开始都可以不做,完全用 bash 弄就行,这两工具纯粹是为了 readonly 的 subagent 准备的)
- 有输入框 + chat view 的 TUI(到这一步,已经是个可用的 coding agent 了,用 Go 写,大概能控制在 3k 行内。对做 agent,不要浪费时间去看各种 framework 了,毫无意义)
- 完善工具(WebFetch、WebSearch、AskUserQuestion)
- TUI 优化:输入历史、
@搜索功能、可视区域动态渲染、上下文使用统计 - 基于磁盘的 session 机制,session 恢复功能
- 动态上下文(初始化项目 .tachi.md 支持),system reminder 支持(告诉 llm 当前时间、工作目录等信息)
- MCP Server 支持
- 微信 channel 支持
- session title 生成,/commit 命令
- SubAgent 支持 + 并行 tool 执行
- TUI 支持 transcript 导出
- llm 执行过程中的 steer 机制支持
- channel 模式支持 cron
- channel 模式支持 /v 模式(输出 tool 执行过程),支持 steer
- skill 系统
- channel 支持接收用户文件,支持导出 transcript
- 支持运行 terminal-bench2.1(没全跑,太慢了,弄环境太费时间,随机找几个 task 能跑成功就行)
- 支持手动 compact
- 支持 memory 后端(mem9)
- MCP tool 支持延迟加载
- channel 模式支持让 llm 主动发文件
- 实现 ACP
几个感受
- Agent framework 毫无意义。AI coding 的时代,framework 只会束缚你的上限。
- 我不懂 harness,只知道三件事:
- 在合适的时候给 LLM 需要的 context
- 让 LLM 别动它不该动的东西
- 不要设计 workflow,毫无卵用,转换成 skill
- 就 coding 这件事,国内外模型的能力差距没那么大。就我个人而言,生成速度 > 智商。
- 少给 agent 做 UI,打磨越多越没意义。
开发过程中感觉没太大用处、所以没实现(或优先级很低)的事:
- LSP:基于 rg 的 Grep 完全够用,LSP 徒增复杂度
- plan 模式:现在 LLM 的指令遵循能力很强了,真没必要单出一个 plan 模式,让它写文档,然后聊着改文档,最后按文档实现就行
- sandbox:纯个人使用,目前 sandbox 意义有限
25 年 3 月,我用 aider 重写 gospy 的时候,其实已经很惊喜了(gospy dev note2: rewrite with aider)。
不过 gospy 的项目规模很小,只有不到 3k 行。那时候 AI coding 的能力还停留在辅助编程,完全没法主导项目。大概从去年年底开始,AI 的确已经可以 100% 完成代码编写这件事了——当然实际项目情况复杂得多……写代码本来也不是最困难的那部分,而那些部分,AI 还没推进到。
我现在的流程比较接近 spec driver:先聊方案,聊方案是为了让自己看明白,然后再执行。AI 生成的代码不会 100% review,先手动跑一遍,能跑起来再说,不对就让 AI 自己加 log、自己分析,实在不行再人看。不会去抠每个功能的代码细节,但会持续关注项目结构——god object 该拆的就拆,该隔离的模块尽早隔离。
代码可以 AI 写,项目推进过程中的思考也可以 AI 来,但反思这件事,目前还是要靠人,所以姑且记一下。